Xonai Shuffle Manager¶
This page introduces the Xonai shuffle manager and documents the steps to activate it.
Introduction¶
The Xonai shuffle manager is a new shuffle manager available in the Xonai Accelerator and co-designed with the Xonai custom compiler to remove the need to sort data in the default Spark sort shuffle manager, which reduces a significant amount of JVM memory.

The shuffle optimization is automatically activated if the plan preceding the Exchange plan is an aggregation (e.g. HashAggregate) and both are supported by the Xonai Accelerator.
The Xonai Accelerator will efficiently partition and sort data while aggregating to make the data ready to be sent directly to the network, bypassing the resource-intensive repartition and sorting process performed in the default Spark shuffle manager.
Prerequisites¶
The Xonai shuffle manager functions just like any other Spark shuffle manager and the JAR containing it must be in the driver and executor class path on application startup, meaning that a copy of the Xonai Accelerator JAR must be available in both nodes.
To activate the Xonai shuffle manager, the following Spark properties must be set as follows:
spark.driver.extraClassPath=<local-path-to-xonai-accelerator-jar>
spark.executor.extraClassPath=<local-path-to-xonai-accelerator-jar>
spark.shuffle.manager=com.xonai.spark.ShuffleManager
Advantages¶
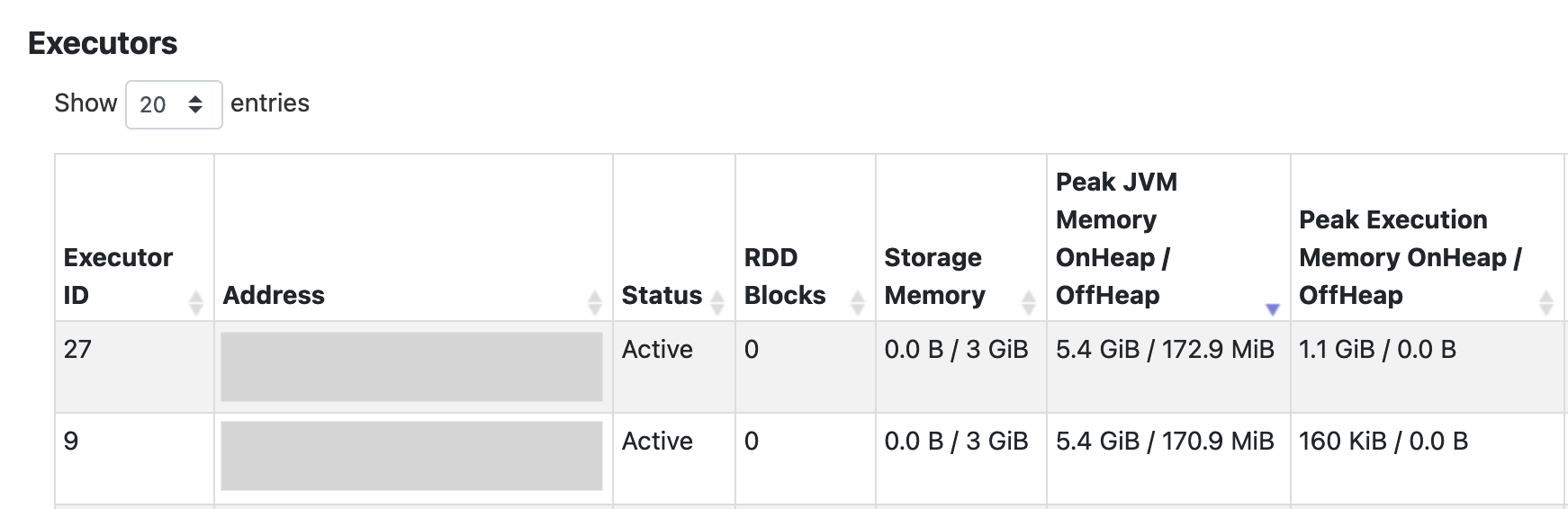
The primary advantage is JVM memory reduction, which can be as much as 2X less JVM peak memory when expensive shuffle exchange operations are present, and this can be verified via the history server Executors tab or the Xonai profiling page.
For the Executors tab, click show additional metrics and select Peak JVM Memory OnHeap / OffHeap and Peak Execution Memory OnHeap / OffHeap.

And then the metrics can be seen in the table below:
Additionally, the Xonai Accelerator adds metrics to the Exchange operation that accurately measures the time it takes to write data, which in normal circumstances should be lower as data does not need to be sorted.