Activate on Job Compute¶
You can activate the Xonai Accelerator on job compute clusters after you have installed Xonai in a Unity Catalog volume.
The first step is to define the Xonai init script you created:
Navigate to Job Runs > Jobs from the left navigation panel in Data Engineering section.
Click in the job you want to activate the Xonai Accelerator.
Click Compute > Configure in the right panel.
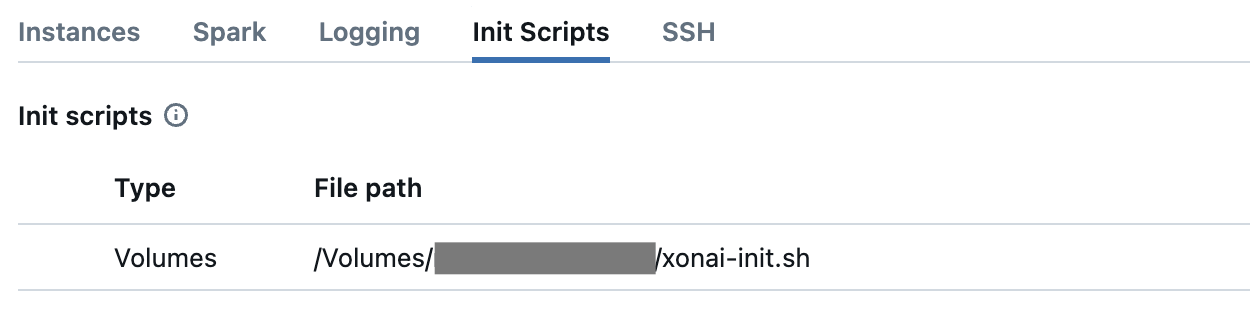
Click Advanced options to expand the section and then click Init Scripts tab.
Select Volume as Source and then select the Xonai init script you created.
On completion it should look like this:
Note
If you installed Xonai on DBFS, select the xonai-init.sh from the Workspace path instead.
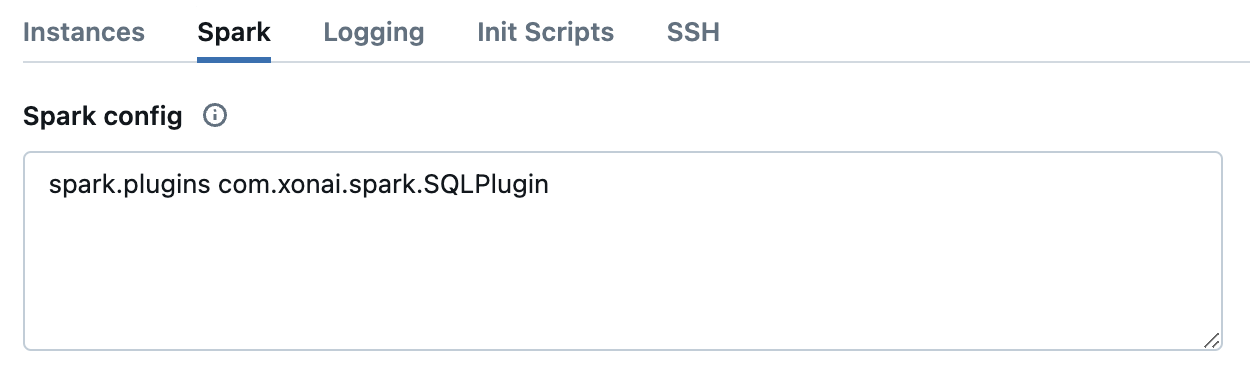
The second step is to define the required configuration for your Spark jobs. In the same Advanced options section, click Spark tab and copy the following code to Spark config.
spark.plugins com.xonai.spark.SQLPlugin
On completion it should look like this:
Your cluster is now configured to run the Xonai Accelerator in your Spark jobs.